목차를 클릭해서 이동해보세요^⏝^
정렬
일반적으로 정렬시켜야 할 대상을 레코드라고 한다. 레코드는 다시 필드라고 하는 단위로 나누어진다. 여러 필드 중에서 특별히 레코드를 식별해주는 역할을 하는 필드를 키라고 한다. 정렬이란 결국 레코드들을 키 값의 순서로 재배열 하는 것이다.
정렬 알고리즘은 크게 2가지로 나눌 수 있다. 자료의 개수가 적다면 단순한 정렬 방법을 사용해도 괜찮지만, 자료의 개수가 일정 개수를 넘어가면 반드시 효율적인 알고리즘을 사용해야 한다.
- 단순하지만 비효율적인 방법: 삽입 정렬, 선택 정렬, 버블 정렬 등
- 복잡하지만 효율적인 방법: 퀵 정렬, 히프 정렬, 합병 정렬, 기수 정렬 등
정렬 알고리즘은 내부 정렬(internal sorting)과 외부 정렬(external sorting)로 구분할 수도 있다.
- 내부 정렬: 정렬하기 전에 모든 데이터가 메인 메모리에 올라와 있는 정렬
- 외부 정렬: 외부 기억 장치에 대부분의 데이터가 있고 일부만 메모리에 올려놓은 상태에서 정렬을 하는 방법
정렬 알고리즘에서 안정성이란 입력 데이터에 동일한 키 값을 가지는 레코드가 여러 개 존재할 경우, 이들 레코드의 상대적인 위치가 정렬 후에도 바뀌지 않는 것을 말한다. 정렬의 안정성이 필수적으로 요구되는 경우에는 안정성을 충족하는 삽입 정렬, 버블 정렬, 합병 정렬 등을 사용해야 한다.
선택 정렬(Selection Sort)

비어있는 리스트 A와, 정렬하고자 하는 리스트 B가 있다고 가정하자. 리스트 B에서 가장 작은 숫자를 선택하여 리스트 A로 이동하는 작업을 되풀이 하는 과정을 리스트 B가 공백 상태가 될 때까지 반복하는 것을 선택 정렬이라고 한다. 이러한 방법을 구현하기 위해서는 입력 배열과 크기가 같은 배열이 하나 더 필요하기 때문에 쓸모없는 메모리를 더 사용해야 된다는 단점이 있다.

이러한 단점을 해결하기 위해 입력 배열 이외에 다른 추가 메모리를 요구하지 않는 제자리 정렬(in-place sotring) 방법이 있다. 입력 배열에서 최솟값을 찾은 뒤 맨 앞의 요소와 변경하는 것을 반복해주면 된다. 즉, ① 0~(N-1)에서의 최솟값과 첫번째 요소를 교환한다. ② 1~(N-1)에서의 최솟값과 두번째 요소를 교환한다... 를 반복해주는 것이다.

특징
- (N - 1)번 진행된다. (N - 1)번째에 마지막 요소는 알아서 가장 큰 요소로 배치되기 때문이다.
- 2중 for문을 사용해서 정렬하기 때문에 시간 복잡도는 $O(n^2)$ 가 된다.
- 안정성을 만족하지 않는다.
코드
void select_sort() {
for (int i = 0; i < SIZE - 1; i++) {
int min = i;
for (int j = i + 1; j < SIZE; j++) {
if (arr[j] < arr[min]) {
min = j;
}
}
swap(i, min);
}
}삽입 정렬(Insert Sort)

정렬되어 있는 리스트에 새로운 레코드를 적절한 위치에 삽입하는 과정을 반복한다. 빈 배열을 하나 더 생성해 정렬하는 것이 아니라, 선택 정렬에서 제자리 정렬을 진행한 것처럼 입력 배열을 정렬된 부분과 정렬되지 않은 부분으로 나누어서 정렬한다. 정렬되어 있지 않은 부분의 첫 번째 숫자가 정렬된 부분의 어느 위치에 삽입되어야 하는가를 판단한 후, 해당 위치에 이 숫자를 삽입한다.

특징
- 0번째 요소는 이미 정렬됐다고 가정한 후, 1번째 요소부터 삽입할 자리를 찾는다.
- 입력 배열이 역순인 경우(최악의 경우) 2중 for문을 전부 돌기 때문에 시간 복잡도는 $O(n^2)$ 가 된다.
- 레코드 양이 많고 레코드 크기가 클 경우 적합하지 않다.
- 대부분의 레코드가 이미 정렬되어 있는 경우에 매우 효율적이다.
- 안정성을 만족한다.
코드
void insert_sort() {
for (int i = 1; i < SIZE; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}코드로 구현하게 되면 간단하게 삽입되는 것이 아니라 내가 삽입될 위치를 찾고, 삽입될 위치부터 뒤에 있는 요소들을 다 한칸씩 미뤄주어야 한다. 따라서 멀리 이동할수록 해야되는 작업이 많아진다.
버블 정렬(Bubble Sort)
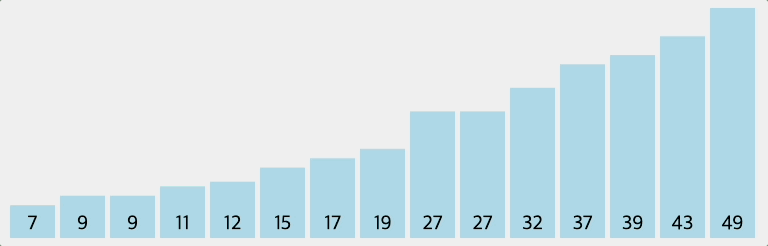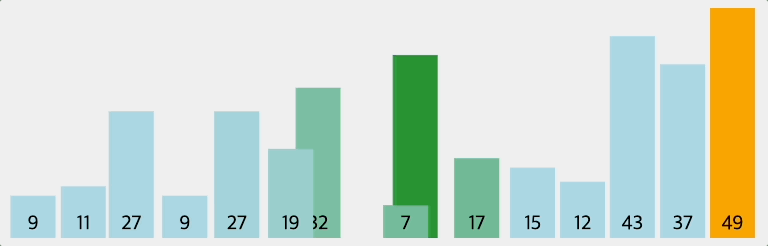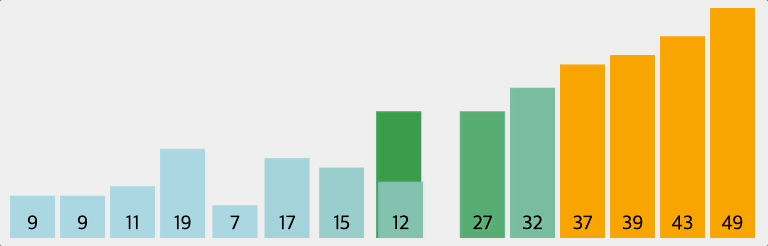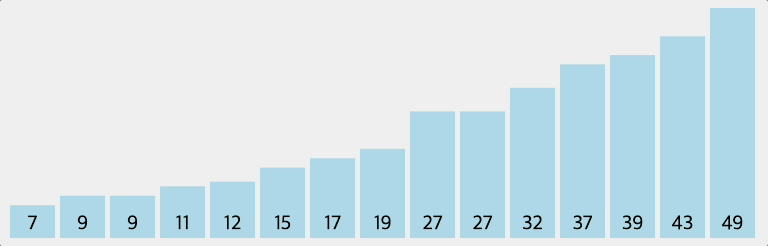
인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 교환하는 비교-교환 과정을 리스트의 왼쪽부터 오른쪽까지 진행하는 정렬 방법이다. 이러한 과정이 한번 완료되면 가장 큰 레코드가 리스트의 오른쪽 끝으로 이동한다. 즉, 버블 정렬을 진행할수록 배열의 오른쪽부터 정렬된다.

특징
- (N - 1)번 진행된다. (N - 1)번째에 첫번째 요소는 알아서 가장 작은 요소로 배치되기 때문이다.
- 2중 for문을 사용해서 정렬하기 때문에 시간 복잡도는 $O(n^2)$ 가 된다.
- 하나의 요소가 가장 왼쪽에서 가장 오른쪽으로 이동하기 위해서는 배열의 모든 요소와 교환되어야 하는 문제점이 있다. 일반적으로 자료의 교환(SWAP) 작업이 자료의 이동 작업보다 더 복잡하기 때문에 버블 정렬은 단순하지만 거의 쓰이지 않는다.
코드
void bubble_sort() {
for (int i = 0; i < SIZE - 1; i++) {
for (int j = 0; j < SIZE - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
swap(j, j + 1);
}
}
}
}쉘 정렬(Shell Sort)
쉘 정렬은 Donald L. Shell이라는 사람이 제안한 방법으로, 삽입 정렬이 어느정도 정렬된 배열에 대해서는 대단히 빠른 것에 착안한 방법이다. 삽입 정렬에서 내가 삽입될 위치가 멀리 떨어진 경우에는 많은 이동을 해야 하지만, 쉘 정렬에서는 멀리 떨어진 위치로도 이동할 수 있다.
쉘 정렬은 전체의 리스트를 한번에 정렬하지 않는다. 대신에 먼저 정렬해야할 리스트를 일정한 기준에 따라 분류하여 ① 연속적이지 않은 여러 개의 부분 리스트를 만들고, ② 각 부분 리스트를 삽입 정렬을 이용하여 정렬한다. 모든 부분 리스트가 정렬되면 다시 전체 리스트를 더 적은 개수의 부분 리스트로 만든 후에 해당 작업을 반복한다. 이 과정은 부분 리스트의 개수가 1이 될 때까지 되풀이한다.
부분 리스트를 만들 때에는 간격을 특정한 수로 정해서 만든다. 이때의 간격을 gap이라고 한다. 각 step 마다 gap을 줄여가며 진행한다. (보통 간격은 1/2 줄인다. 간격이 짝수인 경우 1을 더하는 것이 좋다고 한다.) 즉, 진행될수록 부분 리스트의 개수는 증가한다. 마지막 step에서는 gap이 1이다. 그림을 보면 한 번에 이해할 수 있다!

특징
- 부분리스트에서 교환이 일어날 때 삽입 정렬에 비해 큰 거리를 이동한다. 따라서 교환되는 값들이 삽입 정렬보다는 최종 위치에 더 가까이 있을 가능성이 높아진다.
- 부분 리스트는 어느정도 정렬이 된 상태이기 때문에 gap이 1에 도달한 경우 삽입 정렬을 수행했을 때 빠르게 진행된다.(삽입 정렬은 어느정도 정렬이 된 배열에서 성능이 더 좋다.)
- 시간 복잡도는 최악의 경우 $O(n^2)$ 이지만 평균적인 경우에는 $O(n^{1.5})$ 로 나타낸다.
합병 정렬(Merge Sort)

합병 정렬은 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트를 얻고자 하는 것이다. 합병 정렬은 분할 정복(Divide and Conquer) 기법에 바탕을 두고 있다. 분할 정복 기법은 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다. 이때 문제는 더이상 나눌 수 없을 때까지 분할한다.
합병 정렬은 다음의 단계들로 이루어진다.
1. 분할(Divide): 입력 배열을 2개의 크기가 같은 부분 배열로 분할한다.
2. 정복(Comquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 다시 분할한다.(순환 호출 사용)
3. 결합(Combine): 정렬된 부분 배열을 하나의 배열로 통합한다.
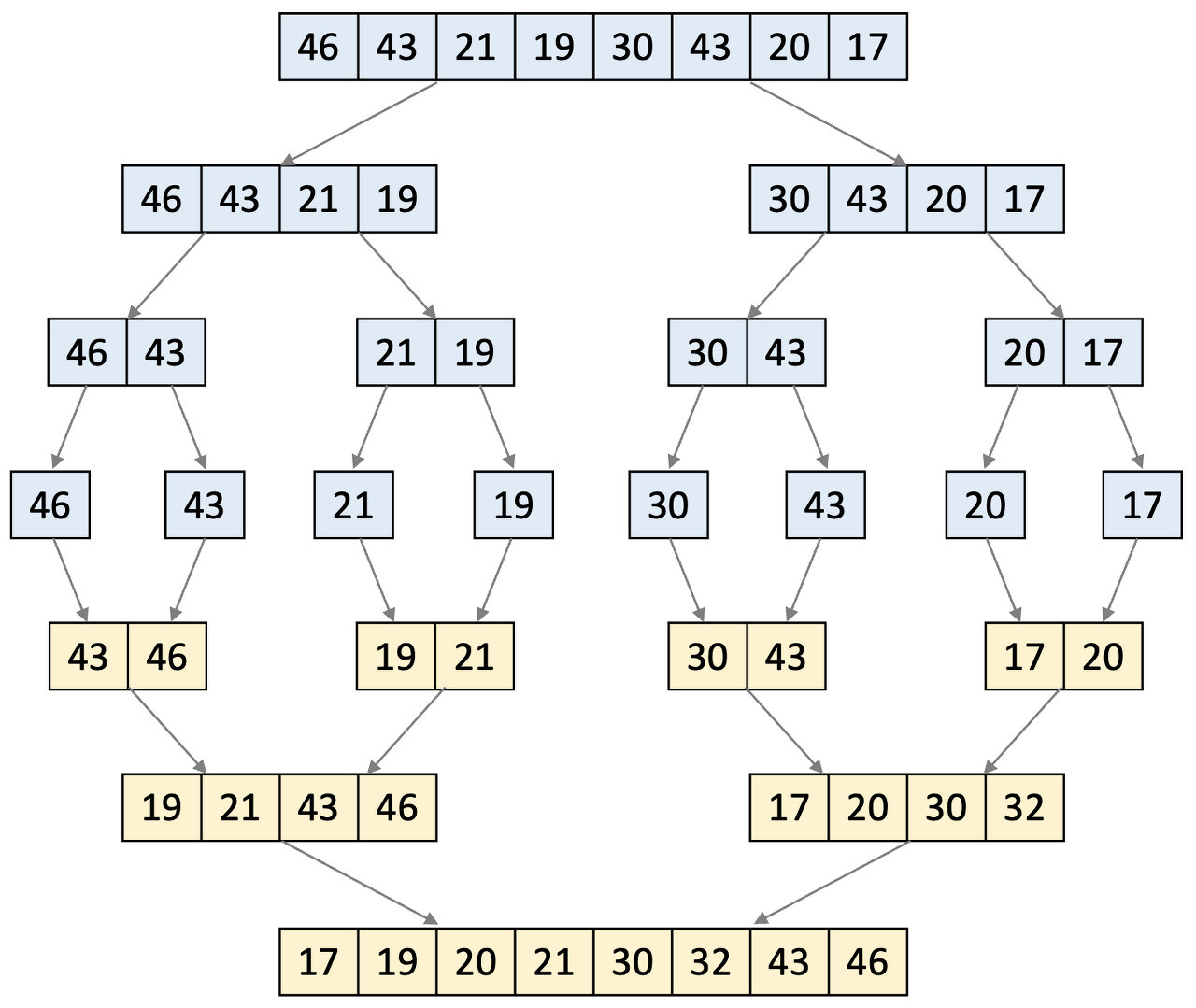
분할하는 것은 재귀 함수를 계속해서 호출하면 된다. 합병은 2개의 리스트의 값을 앞에서부터 비교해 둘 중 더 작은 값을 새로운 리스트로 옮긴다. 둘 중 하나의 리스트가 먼저 끝나면 남아있는 요소들을 모두 옮겨주면 끝난다. 즉, 합병을 위해서는 추가적인 리스트가 필요하다. 또한 합병이 끝난후 이 리스트를 원본 리스트에 복사해주어야 한다.
특징
- 실제로 정렬이 이루어지는 시점은 분할된 리스트를 합병하는 단계이다.
- 최악, 평균, 최선의 경우 모두 시간 복잡도는 $O(nlog_2n)$ 이다.
- 임시 배열이 필요하고, 레코드들의 크기가 큰 경우 이동 횟수가 많아 시간이 오래 걸린다는 단점이 있다. 하지만 배열이 아니라 연결 리스트를 사용해 구성한다면 링크 인덱스만 변경되므로 다른 어떤 정렬 방법보다 효율적일 수 있다.
퀵 정렬(Quick Sort)

퀵 정렬도 합병 정렬과 마찬가지로 분할-정복법에 근거한다. 합병 정렬과 비슷하게 전체 리스트를 2개의 부분 리스트로 분할하고, 각각의 부분 리스트를 다시 퀵정렬하는 전형적인 분할-정복법을 사용하지만, 합병 정렬과 다르게 리스트를 비균등하게 분할한다. ① 먼저 리스트 안에 있는 한 요소를 pivot으로 선택한다. ② pivot보다 작은 요소들은 모두 pivot의 왼쪽으로, pivot보다 큰 요소들은 모두 pivot의 오른쪽으로 옮겨진다. 이때 ③ pivot의 왼쪽과 오른쪽을 다시 정렬하게 되면 전체 리스트가 정렬된다. 합병 정렬과 마찬가지로 나눌 수 있을 때까지 계속 나눈다는 것을 잊지말자.

이러한 배열이 있다고 가정하자. pivot은 배열의 첫번째 요소 5로 정했다. 여기서 low는 왼쪽 부분 리스트를 만드는데 사용되고, high는 오른쪽 부분 리스트를 만드는데 사용된다. low는 왼쪽->오른쪽으로 탐색하다가 pivot보다 값이 큰 데이터를 찾으면 멈춘다. 반대로 high는 오른쪽->왼쪽으로 탐색하다가 pivot보다 값이 작은 데이터를 찾으면 멈춘다. 이때 서로의 데이터를 교환해주면 된다.
쉽게 생각하면, low는 왼쪽 부분 리스트를 만들어야 하는데 pivot과 큰 값이 있어서 멈췄고 high도 마찬가지로 pivot보다 작은 값이 있어서 멈췄다. 서로 있으면 안되는 데이터이기 때문에 교환해주면 된다.

퀵 정렬의 전체 과정은 아래와 같다. 빨간색이 이번 턴에 정해진 pivot이다. 여기서 한 가지 알 수 있는데, 리스트에서 pivot을 선정할 때 리스트의 가장 작거나 큰 값이 pivot이 되는 경우 비효율적이라는 것을 알 수 있다. 여기서는 1과 9가 pivot이 된 경우를 생각하면 된다.

특징
- 계속 불균등하게 나누어지는 경우 $O(N^2)$ 의 시간 복잡도를 가진다. (최악의 경우)
- 하지만 퀵 정렬의 평균적인 시간 복잡도는 $O(nlog_2_n)$ 이다. 특히 같은 시간 복잡도를 가지는 다른 정렬 알고리즘보다 빠르다. 이는 퀵 정렬이 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환할 뿐만 아니라, 한번 결정된 pivot들이 추후 연산에서 제외되는 특성 등에 기인한다.
- 정렬된 리스트에 대해서는 오히려 수행시간이 더 많이 걸린다.
- 리스트의 중앙을 분할할 수 있는 데이터를 pivot으로 선택하면 불균형 분등을 해결할 수 있다.
히프 정렬(Heap Sort)
히프는 최댓값이나 최솟값을 쉽게 추출할 수 있는 자료구조이다. 최소 히프를 사용하게 되면 부모 노드의 값이 자식 노드의 값보다 작기 때문에 최소 히프의 루트 노드는 가장 작은 값을 가지게 된다. 이러한 특성을 이용해 정렬할 배열을 먼저 최소 히프로 변환한 다음, 가장 작은 원소부터 차례대로 추출하며 정렬하는 방법을 히프 정렬이라고 한다.
특징
- 히프 정렬의 특징은 히프의 특징이기 때문에 따로 작성하지는 않겠다.
기수 정렬(Radix Sort)

기수(radix)란 숫자의 자리수를 말한다. 기수 정렬은 레코드를 비교하지 않고도 정렬할 수 있다. 정렬에 기초한 방법들은 절대 $O(nlog_2_n)$이라는 이론적인 하한선을 깰 수 없는데 반하여 기수 정렬은 이 하한선을 깰 수 있는 유일한 기법이다. 하지만 기수 정렬은 추가적인 메모리를 필요로 한다. 또한, 기수 정렬은 레코드의 키들이 동일한 길이를 가지는 숫자나 문자열로 구성되어야만 된다.
십진수에서는 각 자리수가 0~9로 제한된다. 따라서 기수 정렬에서는 10개의 버킷을 만들어 해당 버킷에 숫자들을 넣어준 후, 0번 버킷부터 순서대로 읽어오는 방법을 사용해 정렬을 수행한다. 만약 여러 자리로 이루어진 수는 각 자릿수마다 비교하면 될 것이다. 이때 1의 자리수를 먼저 비교해야 한다.

특징
- d개의 자리수를 가지는 n개의 수가 존재한다면 $O(d * n)$ 의 시간 복잡도를 가진다. 즉, d에 비례하기 때문에 정수의 크기와 관련이 있다. 하지만 일반적으로 10개 정도의 자리수를 가지므로 시간 복잡도는 $(O(n)$ 이라고 해도 무방하다.
- 한글, 한자 등으로 이루어진 키 값을 기수 정렬 하고자 할 경우에는 매우 많은 버킷이 필요하다.
'Study > CS' 카테고리의 다른 글
| [AWS] 리전, 가용 영역, 에지 로케이션의 개념 (0) | 2023.11.02 |
|---|---|
| 디지털 전환(DX)의 개념 (0) | 2023.10.11 |
| 마이크로서비스의 개념 (0) | 2023.10.08 |
| 컨테이너와 컨테이너 오케스트레이션의 개념 (0) | 2023.08.29 |